武科大网讯 近日,我校计算机学院ONTOWEB研究团队联合哥本哈根大学Daniel Hershcovich教授、香港科技大学(广州)吴逊教授在人工智能与文化价值对齐研究领域取得系列重要进展,围绕“大型语言模型如何准确理解并尊重多元文化价值”这一核心命题,3篇高水平论文被国际顶级会议与期刊录用,分别发表于NAACL 2025(人工智能领域高水平会议)、EMNLP 2025(人工智能领域顶会,CCF-B会议)以及Elsevier的IP&M 期刊 (SCI一区及CCF-B期刊),并同步向国内外学术界开放代码与数据。上述成果获得新加坡国立大学和腾讯公司共同举办的“科技向善:推动社会影响”全球开发研究项目资助。
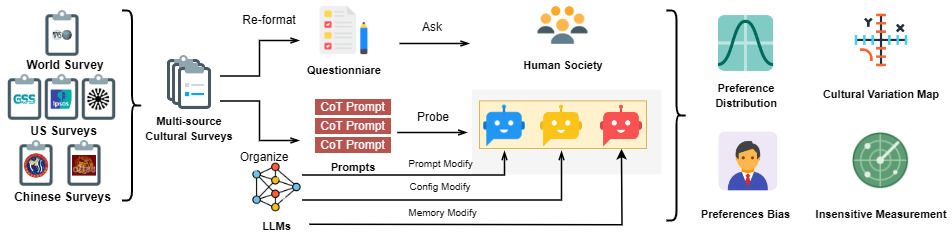
图1 评估体系流程图
第一项研究,团队聚焦于评估体系自身的科学性与严谨性。调研发现,现有文化价值对齐评测往往忽视了大模型输出在情境扰动下的多样性不足问题,可能导致结论失真。为此,研究提出了多样性增强框架(DEF,如图1所示),通过城市级情境采样、记忆长度随机截断与解码参数扰动三重机制,放大潜在差异并量化其影响。基于1,153道中美主流社会调查题目的综合实验表明,该框架可将模型回答多样性提升近九成,并首次在系统层面揭示了性别与年龄维度的偏好偏差,为后续公平性改进提供了可操作的度量基准。
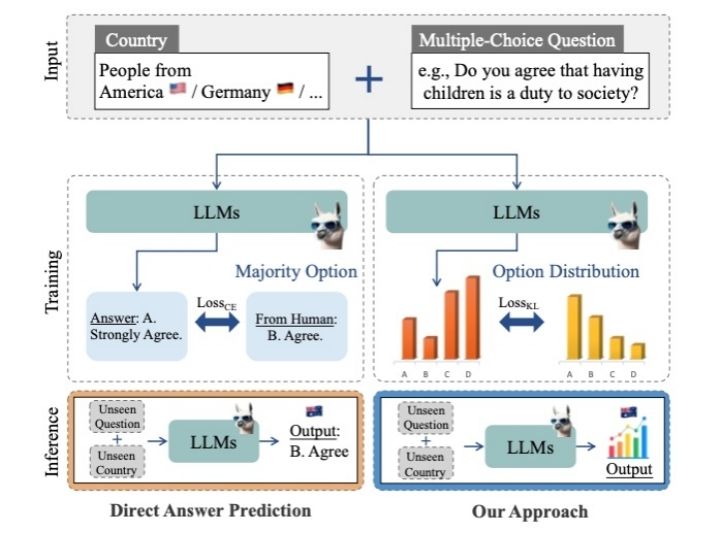
图2 首词概率分布对齐微调方法
第二项研究,团队针对全球价值观调查所面临的高成本、长周期难题,提出了一种基于首词概率分布对齐的微调方法(图2),使大模型得以在未曾开展实地调查的国家与问卷上生成与人类统计特征高度一致的响应分布。实验覆盖世界价值观调查2017—2022周期65个国家、259道题目,结果表明该方法可将预测误差显著降低,并在完全未见的问题与国家场景上保持稳健,为跨文化社会研究提供了可迁移、可扩展的新范式。
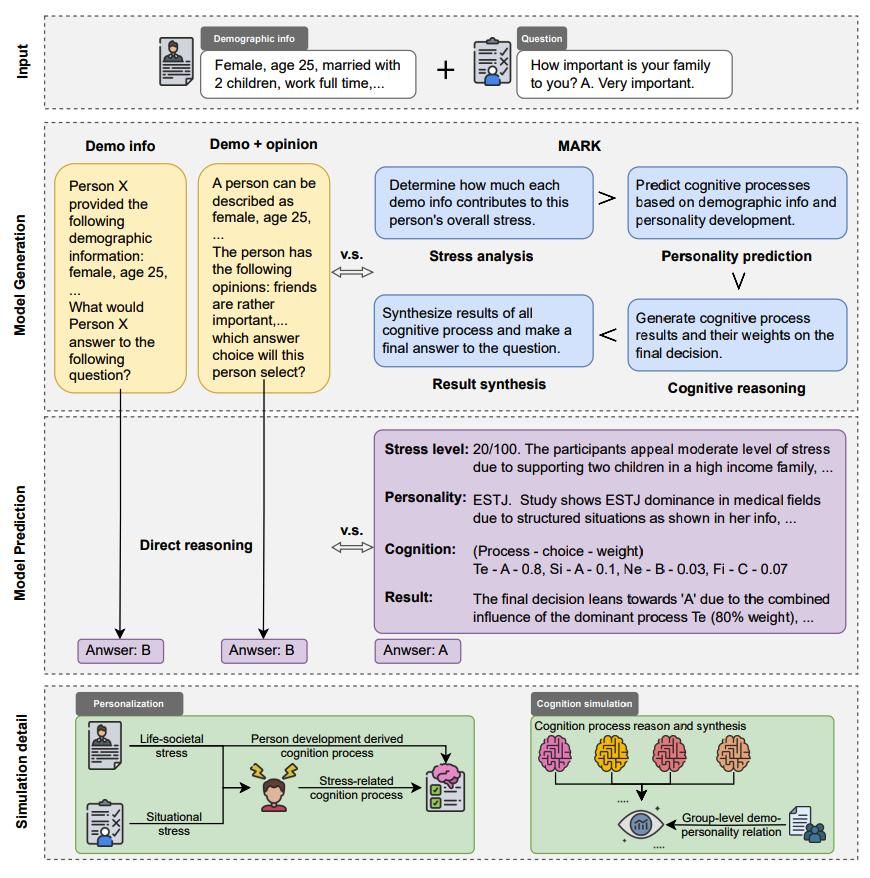
图3 多阶段认知推理框架MARK
第三项研究,团队进一步将研究视角从宏观群体转向微观个体,系统反思了传统“人口标签”式提示策略可能导致的刻板印象风险。团队借鉴人格心理学理论,构建了名为MARK的多阶段认知推理框架(图3),通过先评估个体情境压力,再推断其认知功能偏好,进而模拟不同心理过程在问卷作答中的动态交互,最终输出兼具解释性与准确性的答案。在中美双文化数据集上的实验显示,该框架可将预测准确率提升约十个百分点,同时显著减少模型对性别、年龄等显性特征的机械依赖。
上述三项研究层层递进,形成了从“评估方法自省”到“宏观分布模拟”再到“微观心理建模”的完整研究闭环,标志着我校在人工智能与社会科学交叉领域迈出了坚实步伐。ONTOWEB研究团队将继续秉持“严谨、开放、共享”的科研理念,深入推进大模型文化价值对齐的理论深化与技术落地,为全球数字人文研究与国家数字治理体系建设贡献武科大智慧。









