武科大网讯 近日,我校计算机学院ONTOWEB研究团队在AI辅助中华典籍理解方面取得阶段性重要成果——在参数规模不足传统大模型十分之一的轻量级架构上,仍可显著超越现有大模型对文言文的理解精度。该成果以“小模型高效理解文言文”为目标,围绕古籍数字化、传统文化传承以及移动端智能应用的迫切需求,在语义对齐、语料构建与跨模态表征三个维度形成了完整的方法学闭环。相关论文相继被ACM TALLIP (2023)、SCI一区期刊Information Processing & Management (2024)与AI顶会ACL 2025录用。
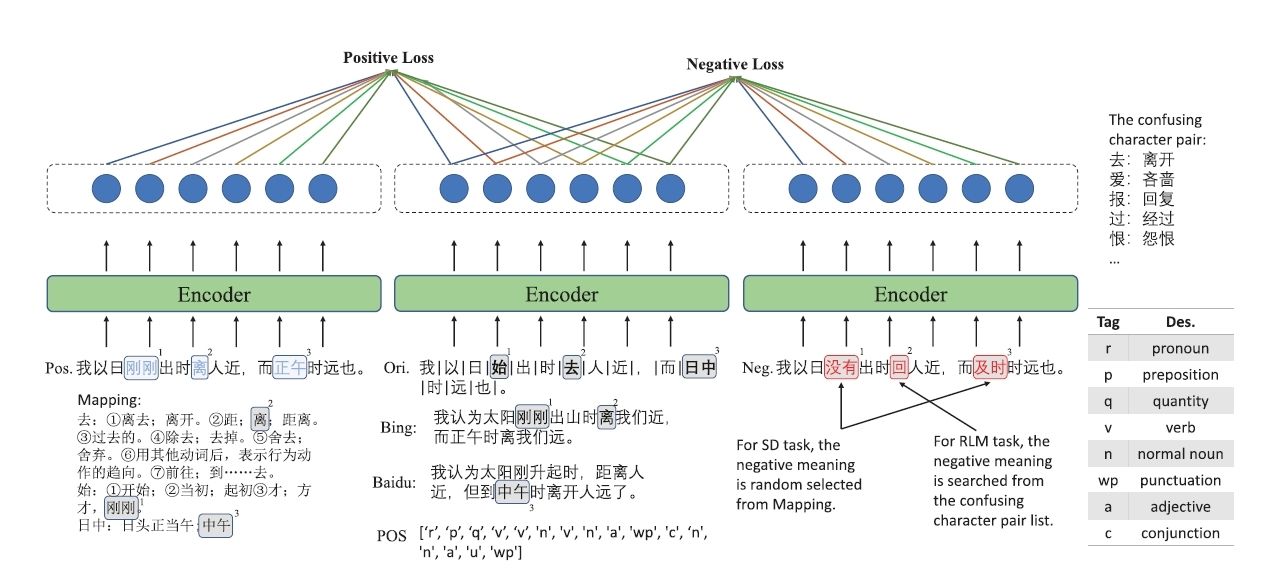
图1 基于对比学习的同义词判别预训练任务
针对文言文本与现代问答之间固有的历时性语义鸿沟,团队提出基于对比学习的同义词判别预训练任务(图1),通过字级语义距离度量建立古汉语与现代汉语的精准映射;在此之上引入增强双匹配网络,以选项级注意力推理链模拟人类“先比较、后定夺”的阅读过程,在Haihua、CLT、ATRC等公开数据集上取得平均约4%的绝对精度提升,同时将推理时延控制在原有模型的百分之一以内。
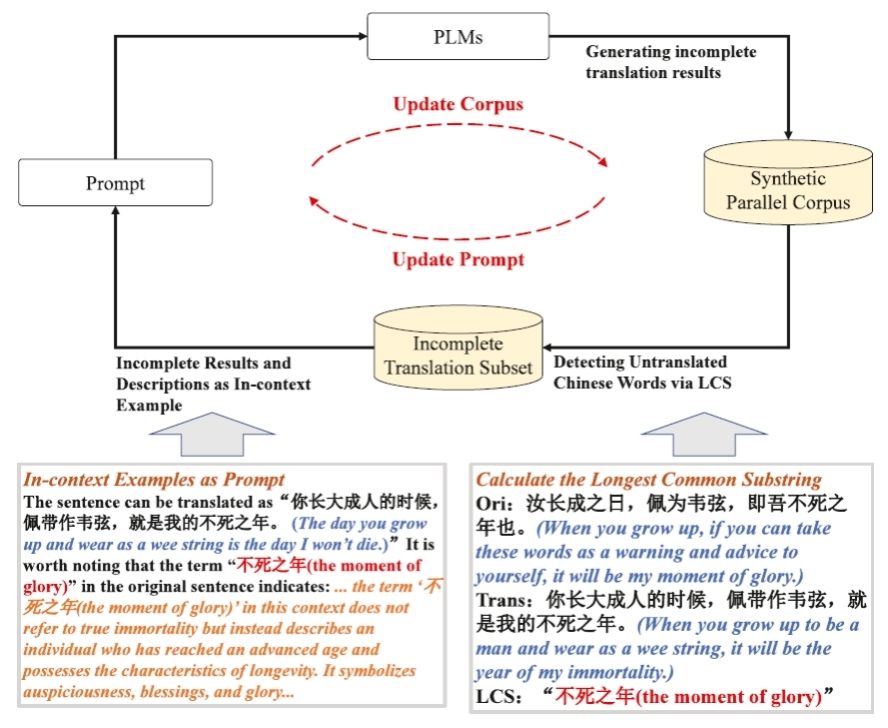
图2 大语言模型驱动的渐进式译文精炼框架
为缓解高质量平行语料稀缺导致的训练瓶颈,团队设计了一套由大语言模型驱动的渐进式译文精炼框架(图2),利用最长公共子串算法自动检测未翻译文言词汇,并通过语义描述示例反复迭代,最终生成规模为37.2 GB、未翻译词比例降至5.8%的高对齐语料库,其构建成本仅相当于传统人工标注的百分之三,却足以支撑小模型的充分训练。
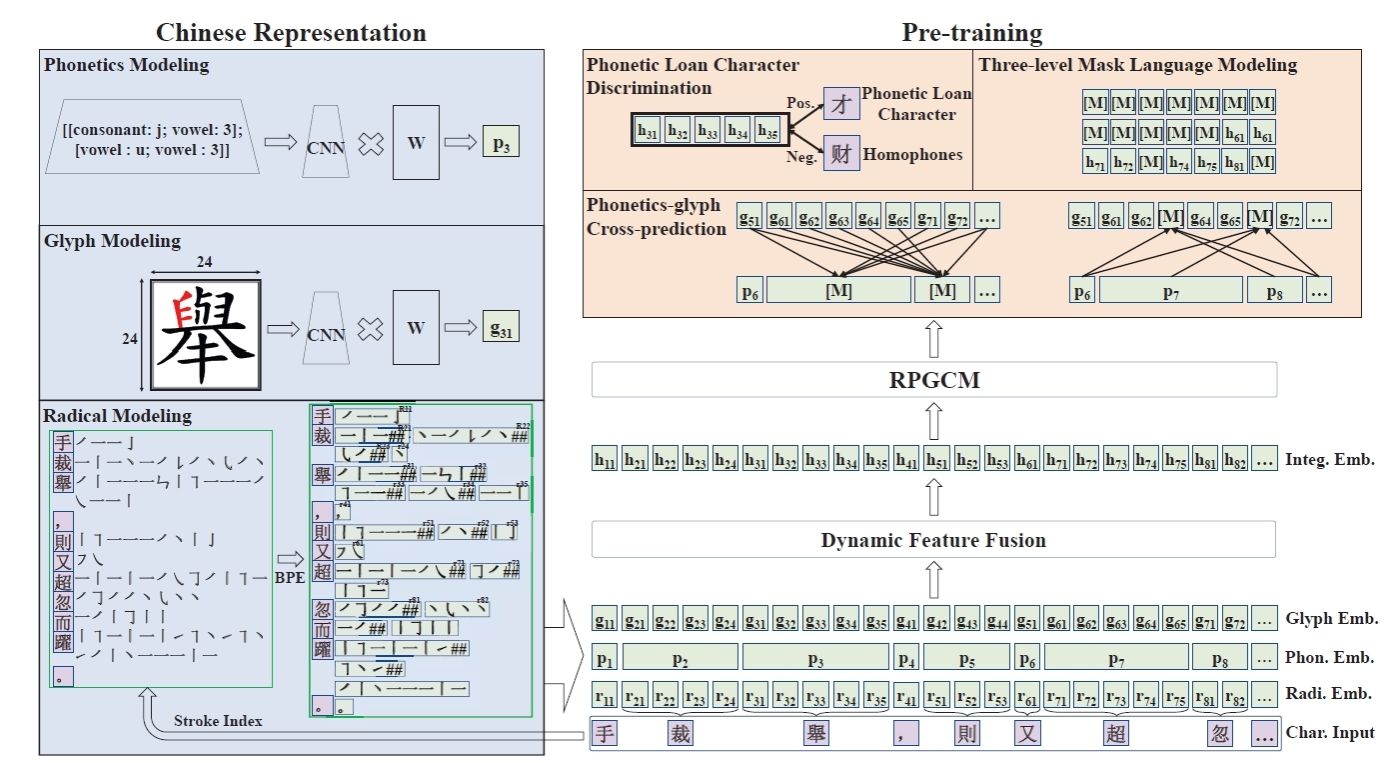
图3 RPGCN框架示意图
在汉字自身的形、音、义协同机制层面,团队首次将部首级音形表征引入古典中文预训练,提出基于笔画序列BPE子词切分、部首字形ResNet编码与多音字拼音CNN编码的跨模态融合策略,辅以通假字判别、三级掩码语言建模与音形互译三大预训练任务(RPGCN),显著缓解了通假、歧义及低频字误读等问题。在C³Bench、WYWEB等综合理解基准的评测中,该轻量级模型均稳定反超基线系统3至7个百分点,验证了形音义联合建模在小参数条件下的有效性。
同时,参与本项目的博士生们已完成“小模型古文引擎”的SDK封装,并成功运行于主流移动终端,离线支持《史记》《资治通鉴》等典籍的实时译文与问答交互。相比传统BERT模型,单页古籍拍照上传后的现代文译文与关键问答准确率可达92%,训练时间降低80%。上述工作为边远地区学校、基层博物馆及公共文化服务机构提供了低成本、可扩展的智能阅读解决方案。









